2D Strategy Game (13): Text
Using the Pygame library, we can draw text with the render() method of the pygame.Font class. However, it does not handle layout and mixed styles: we create a solution that draws a styled text using an HTML-like syntax.
This post is part of the 2D Strategy Game series
We want the following syntax:
Test<br>
<i>Italic</i><br>
<b>Bold</b><br>
<u>Underline</u><br>
<i><b><u>All</u></b></i><br>
<s color="warning">Color</s><br>
Icon:<dungeon>to generate this result:

Text tokenizer
In text parsing, a common (and very good!) approach uses tokenization. The idea is to translate the raw input text into a list of tokens. Each token holds a text part with similar properties or updates the current rendering setup. For instance, the input text:
<i>Message</i><br>
is converted to four token, for instance:
Style(AddItalic), Content("Message"), Style(RemoveItalic), NextLine
Token classes: we create classes to represent the different token types:
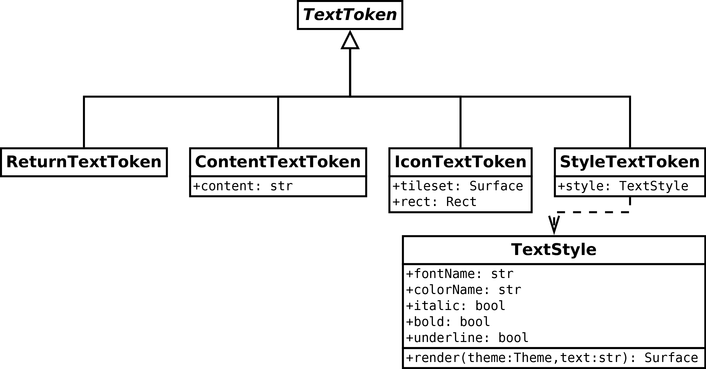
The purpose of these classes is only to store data as we did for the game state. In some cases, we add extra data: for instance, ContentTextToken contains text to render. The StyleTextToken class contains a TextStyle, which holds all the information required to render text in a specific style.
The text tokenizer: the Python library already contains a package to parse HTML data. We use it to create the TextTokenizer class that converts a text to a list of tokens:
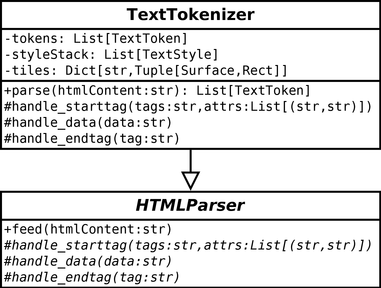
The HTMLParser from the html.parser standard package implements the Visitor pattern. When we call the feed() method, it parses the data, and when something happens, it calls one of the handle_xxx() method. In particular, we consider the following events/methods of HTMLParser:
- The
handle_starttag()method is triggered when a tag starts (like<b>). We create a new text style depending on the tag. For instance, with a<b>, we create a new text style similar to the previous one withboldactivated. We save this new style instyleStackto keep track of all the styles we create. - The
handle_data()method is triggered when there is content. Note that the library handles entities (like<); we don't have to worry about them. In this case, we add a new content token to the list. - The
handle_endtag()method is triggered when a tag ends (like</b>). We check that it is as expected and restore the previous style saved instyleStack.
The parse() method of TextTokenizer prepare the attributes and runs the parsing:
def parse(self, content: str, style: TextStyle) -> List[TextToken]:
self.__styleStack.clear()
self.__styleStack.append(style)
self.__tokens.clear()
self.feed(content)
return self.__tokensWe use the styleStack attribute to store the last used text styles. At the beginning of the process, we add a first style given by the user (line 3). The tokens attribute stores all the tokens we create during the parsing. We ensure that it is empty at the beginning (line 4) and return it at the end (line 6).
The TextTokenizer class also has a tiles attribute that maps a tag to a tile. We initialize it in the constructor:
frame = theme.getTileset("frame")
icons = theme.getTileset("icons")
self.__tiles = {
"dungeon": (frame.surface, frame.getTileRect("dungeon")),
"food": (icons.surface, icons.getTileRect("food")),
}Implementation: we handle the start tags in the handle_starttag() method:
def handle_starttag(self, tag, attrs):
if tag in self.__tiles:
tile = self.__tiles[tag]
token = IconTextToken(tile[0], tile[1])
self.__tokens.append(token)
elif tag == "br":
self.__tokens.append(ReturnTextToken())
else:
currentStyle = self.__styleStack[-1]
newStyle: Optional[TextStyle] = None
if tag == "i":
newStyle = currentStyle.styleItalic()
elif tag == "b":
newStyle = currentStyle.styleBold()
elif tag == "u":
newStyle = currentStyle.styleUnderline()
elif tag == "s":
for name, value in attrs:
if name == "color":
newStyle = currentStyle.styleColor(value)
else:
logging.warning(f"Invalid attribute {name} for <s>")
else:
logging.warning(f"Invalid or unsupported tag {tag}")
if newStyle is not None:
self.__styleStack.append(newStyle)
self.__tokens.append(StyleTextToken(newStyle))The tag argument contains the current starting tag (without the <> symbols). If this tag is one of the icon tiles, we add a new icon token with the corresponding surface/rectangle (lines 2-5). If tag is "br", we add a return/next line token (lines 6-7). Then we assume that all the other tags modify the text style (lines 9-27).
We first get the current style: it is the last element of the style stack (line 9). Then, we init a newStyle variable to None (line 10) and, depending on the tag, we create a new text style with a property activated. We use commodity methods in TextStyle that create these styles. For instance, styleItalic() returns a copy of currentStyle, but with the italic property set as True. For the s tag, we parse all the tag attributes in the attrs argument (like <s color=value>). Each attribute has a corresponding value, and we use it to create new text styles (ex: line 20).
For the handling of content (e.g. text with no tags) in the handle_data() method, we only add a new content token to the list:
def handle_data(self, content):
self.__tokens.append(ContentTextToken(content))The handle_endtag() restores the previous style:
def handle_endtag(self, tag):
self.__styleStack.pop()
self.__tokens.append(StyleTextToken(self.__styleStack[-1]))It could be better to check that start and end tags are consistent: for instance, a <b> always closes a </b>. With this code, we can end a tag with anyone. However, it is more complex, and we don't need this feature for our game.
Render the text
Once the text is "tokenized", we can render it using the render() method of the TextRenderer class:
def render(self, message: str) -> Surface:
tokens = self.__tokenizer.parse(message, self.__style)
x, y = 0, 0
currentStyle = self.__style
surfaceWidth, surfaceHeight = 0, 0
blits: List[Tuple[Surface, Tuple[int, int], Optional[Rect]]] = []
for token in tokens:
...
textSurface = Surface(
(surfaceWidth, surfaceHeight), flags=pygame.SRCALPHA)
for blit in blits:
textSurface.blit(*blit)This method aims to return a Pygame surface with the rendered text. Unfortunately, we can't create it at the start because we don't know its size. So, we update its size in variables (line 5) during the tokens analysis (lines 7-8) and store all the blit arguments in a list (line 6). Then, at the end, we can create the surface (lines 9-10) and run all the blits (lines 11-12).
Note the syntax: *blit. It asks Python to convert all items of a list into method arguments. For example, if blit contains a,b,c, then textSurface.blit(*blit) is equivalent to textSurface.blit(a,b,c).
Depending on their type, we process each token in the for loop. The first case is the content token:
if isinstance(token, ContentTextToken):
contentToken = cast(ContentTextToken, token)
surface = currentStyle.render(
self.__theme, contentToken.content)
height = surface.get_height()
surfaceHeight = max(surfaceHeight, y + height)
blits.append(
(surface, (x, surfaceHeight - height), None))
x += surface.get_width() + 1We use typing.cast() function to create a variable with a more specific type (line 2). Remind that it changes nothing at runtime, but it helps Pycharm and mypy in finding errors. Then, we use the render() method in the TextStyle class to render the text in the token. We call this method using the current text style stored in currentStyle (lines 3-4). We update the rendering properties (lines 5-6 and 9), and adds the arguments of a blit() call to the blits list (lines 7-8).
The icon token case is similar, except that the token contains the properties of the tile to render:
elif isinstance(token, IconTextToken):
iconToken = cast(IconTextToken, token)
surface = iconToken.tileset
rect = iconToken.tile
blits.append((surface, (x, y), rect))
x += rect.width + 1
surfaceHeight = max(surfaceHeight, y + rect.height)For the return/next line token, with only update the next rendering position:
elif isinstance(token, ReturnTextToken):
x, y = 0, surfaceHeight + 2Handling the style token is easy because we did most of the job during the text parsing. We only update the current style with the one stored in the token:
elif isinstance(token, StyleTextToken):
styleToken = cast(StyleTextToken, token)
currentStyle = styleToken.styleFinal program
In the next post, we use Numpy to speed up the game.